Resources
The Basic Encoding Rules (BER) specify how data should be encoded for transmission, independently of machine type, programming language, or representation within an application program.
BER uses a Tag-Length-Value (TLV) format for encoding information. The type or tag indicates what kind of data follows, the length indicates the length of the data that follows, and the value represents the actual data. Each value may consist of one or more TLV-encoded values, each with its own identifier, length, and contents.
While TLV encodings increase the number of octets transferred, it makes it easier to introduce new fields in messages that can be handled even by older implementations. Another advantage is that the predictability of the encoding makes it easy to debug.
![]()
The identifier consists of three parts:
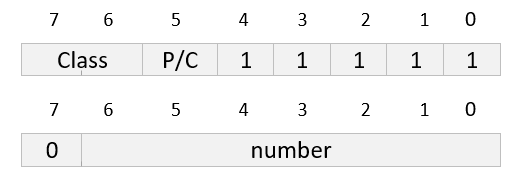
In the following example, BOOLEAN's tag UNIVERSAL 1 is encoded. The encoding is primitive (BOOLEAN contains no other types within it):
![]()
In the second example, the tag PRIVATE 13 has a constructed encoding. This tag can be used, for example, to identify a particular ASN.1 SEQUENCE in some proprietary application. Like the first example, the encoded identifier occupies only a single octet:
![]()
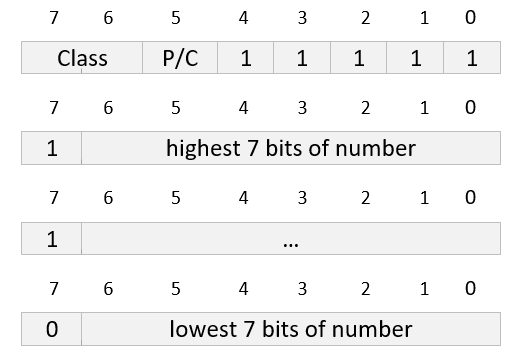
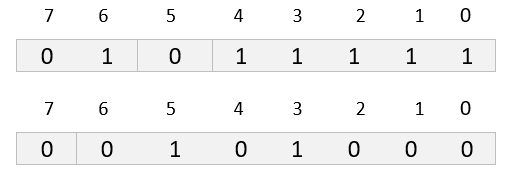
The third example shows a more complex case: a primitive encoding of the tag APPLICATION 40. The first octet of the encoding indicates the identifier's class and encoding (primitive or constructed). The last five bits of this first octet, however, are all 1's, indicating that the tag's number is encoded in the following octets. In this case, only one extra octet is required to contain the tag number 40, so bit 7 of this octet is set to 0. The value 40 is encoded in the rightmost seven bits of this extension octet:
Length is always specified in octets, and includes only the octets in the actual value (the contents). It does not include the lengths of the identifier or of the length field itself.
There are three ways to encode lengths in BER:
In this example, a length of 5 is encoded using the short form. Bit 7 of the single length octet is set to 0, and bits 6-0 contain the binary value 5:
![]()
The second example shows a long form encoding. Bit 7 of the first octet is set to 1, and bits 6-0 contain the value 2. This indicates that the two following octets contain the actual length of the contents. This length, 1020 octets, is then encoded in binary in the last two octets:
In the next example, the long form is used to encode a length of 5. Unlike the previous case, where the short form could not have been used due to the magnitude of the length, the long form is not required here. It is legal, however, to encode any length (up to the maximum) using the long form, and to precede it with any number of leading zero octets. In this example, the first octet of the length has bit 7 set to 1, indicating the long form, and a value of 2 in bits 6-0. This indicates that the following two octets contain the actual length. As the example shows, those two octets consist of one octet of zeros, followed by a 5 encoded in the second octet. A sender can encode all lengths this way to simplify the implementation:
![]()
The final example shows the indefinite form of encoding, which is used only with constructed encodings; a value using indefinite form is likely to contain other length fields for its embedded values. In the example shown, those embedded lengths all use the short form, but they are free to use any style of length encoding. If one or more of the embedded values has a constructed encoding, it can even use the indefinite form. The length field contains the value 8016, followed by the identifier of the first encoded value within this constructed encoding. The end of the constructed encoding is marked with the end-of-contents indicator, two octets of 0's:
![]()
Age ::= INTEGER (0..7) firstGrade Age ::= 6 -- 02 01 06
operationCompleted BOOLEAN ::= TRUE -- 01 01 FF
Married ::= BOOLEAN currentStatus Married ::= FALSE -- 01 01 00
temperatureToday INTEGER ::= 72 -- 02 01 48
Color ::= INTEGER {red(0), blue(1), yellow(2)} defaultColor Color ::= blue -- 02 01 01
Color ::= ENUMERATED { red (0), blue (1), yellow(2) } colorOfTheSky Color ::= blue -- 0A 01 01
MorP ::= ENUMERATED { minus (-1), zero (0), plus (1) } negative MorP ::= minus -- 0A 01 FF
The example shows how the real value 10.0 could be described using this scheme. Note that several different representations of the same real value are possible:
ten REAL ::= { 10, 2, 0 } Value = 10 * 20 or 10.0 M = 10 B = 2 E = 0 M = 1 * 10 * 2 0 S = 1 N = 10 F = 0
Possible contents encoding structure:
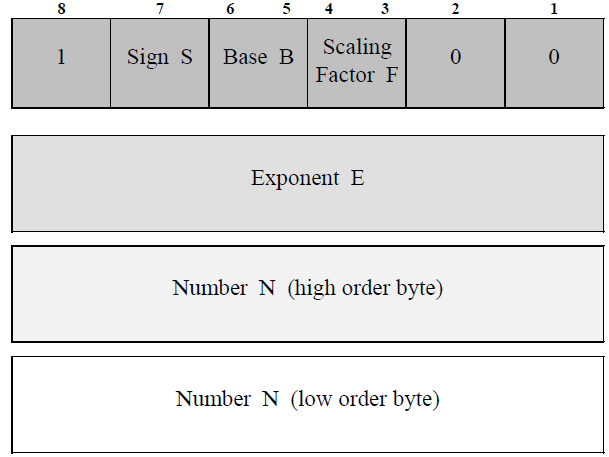
ten REAL ::= { 10, 2, 0 }
-- 09 03 80 00 0A
In the first example, the BIT STRING value is 12 bits long. The first octet of the encoded contents contains the value 4, indicating that the last four bits of the final octet are not part of the actual encoded BIT STRING value. The last two octets contain the actual value, padded with zeros to an octet boundary.
contents2 BIT STRING ::= '101100001001'B -- 03 03 04 B0 90
The second example shows a similar structure. Both encodings are primitive:
Color ::= BIT STRING {red(0), blue(1), yellow(2) } defaultColors Color ::= {red, yellow} -- 03 02 05 A0
The third example shows the special case for a null BIT STRING:
colorless Color ::= ''B -- 03 01 00
The first OCTET STRING example shows a primitive form encoding of a two-octet value:
eightBitBytes1 OCTET STRING ::= 'A24F'H -- 04 02 A2 4F
The second example shows how constructed form encodings are accomplished: the OCTET STRING value is divided into arbitrary length pieces, each encoded as a primitive OCTET STRING. The entire list of these primitive values is then treated as the value (contents) of a single constructed OCTET STRING. This same technique is used when constructed encodings are used with BIT STRING values:
longString OCTET STRING ::= '00112233445566778899AABBCCDDEEFF'H -- 24 80 -- 04 08 00 11 22 33 44 55 66 77 -- 04 08 88 99 AA BB CC DD EE FF -- 00 00
currentlyUnknown ::= NULL -- 05 00
In the following example, in an encoding of a value of the SEQUENCE type PersonnelRecord, the SEQUENCE's identifier and length appear first, followed by the SEQUENCE's contents. Those contents, however, are the SEQUENCE's elements, and are encoded as an OCTET STRING value and two INTEGER values. The encoded elements must appear in exactly the order shown in the type definition:
PersonnelRecord ::= SEQUENCE { name OCTET STRING, location INTEGER { homeOffice(0), fieldOffice(1), roving(2)}, age INTEGER OPTIONAL } rockStar1 PersonnelRecord ::= { name '6269672068656164'H, location roving, age 26} -- 30 10 -- 04 08 62 69 67 20 68 65 61 64 -- 02 01 02 -- 02 01 1A
DailyTemperatures ::= SEQUENCE OF INTEGER weeklyHighs DailyTemperatures ::= {10, 12, -2, 8} -- 30 0C -- 02 01 0A -- 02 01 0C -- 02 01 FE -- 02 01 08
In the following example, the elements location and age are encoded in reverse order from that specified in the type definition. This flexibility in encoding is what requires the context-specific tags to be added to the elements of the SET:
PersonnelRecord ::= SET { name OCTET STRING, location INTEGER { homeOffice(0), fieldOffice(1), roving(2) }, age INTEGER OPTIONAL } rockStar3 PersonnelRecord ::= { name '44617679204A6F6E6573'H, location homeOffice, age 44 } -- A0 12 -- 80 0A 44 61 76 79 20 4A 6F 6E 65 73 -- 82 01 2C -- 81 01 00
In the following example, any value of type Division will be either the SEQUENCE type named manufacturing or the SEQUENCE type named r-and-d. In the value specified, r-and-d is chosen, therefore, the encoding is that of the SEQUENCE defined for r-and-d:
Division ::= CHOICE { manufacturing SEQUENCE { plantID INTEGER, majorProduct OCTET STRING} r-and-d SEQUENCE { labID INTEGER, currentProject OCTET STRING } currentAssignment Division ::= r-and-d : { labID 48, currentProject '44582D37'H} -- A1 09 -- 02 01 30 -- 04 04 44 58 2D 37
targetSales NumericString ::= "1000000" -- 12 07 31 30 30 30 30 30 30 topAuthor PrintableString ::= "Parker" -- 13 06 50 61 72 6B 65 72 letters UTF8String ::= "abcdlmyz" -- 0C 08 61 62 63 64 6C 6D 79 7A
ftam1 OBJECT IDENTIFIER ::= { iso standard 8571 abstract-syntax(2) ftam-pci(1) } -- 06 05 28 C2 7B 02 01 ftamPDUs ObjectDescriptor ::= "FTAM PCI" -- 07 08 46 54 41 4D 20 50 43 49
endOfTime DATE ::= "2012-12-21" -- 1F 1F 08 32 30 31 32 31 32 32 31 zero DATE-TIME ::= "1951-10-14T15:30:00" -- 1F 21 31 39 35 31 31 30 31 34 -- 31 35 33 30 30 30 millenium DURATION ::= "P1000Y" -- 1F 22 05 31 30 30 30 59 dawn TIME-OF-DAY ::= "06:30:00" -- 1F 20 06 30 36 33 30 30 30
